8.1 Enfermedad Coronaria
![]()
| Variable | Descripción | Valores |
|---|---|---|
| ID | Identification code | 1 - 100 |
| AGE | Age | Years |
| AGE_GROUP | Age group | 1: 20-39, 2: 30-34, 3: 35-39, 4: 40-44, 5: 45-49, 6: 50-54, 7: 55-59, 8: 60-69 |
| CHD | Presence of CHD | 1: No, 2: Yes |
Fuente: David W. Hosmer Jr., Stanley Lemeshow, Rodney X. Sturdivant (2013). Applied Logistic Regression, 3rd Edition. ISBN: 978-0-470-58247-3. 528 Pages.
Los primeros datos son:
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| ID | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| AGE | 20 | 23 | 24 | 25 | 25 | 26 | 26 | 28 | 28 | 29 | 30 | 30 |
| AGE_GROUP | 20-39 | 20-39 | 20-39 | 20-39 | 20-39 | 20-39 | 20-39 | 20-39 | 20-39 | 20-39 | 30-34 | 30-34 |
| CHD | No | No | No | No | Yes | No | No | No | No | No | No | No |
| Fuente: https://rdrr.io/cran/aplore3/man/chdage.html |
El conjunto de datos nos dice:
| No | Variable | Stats / Values | Freqs (% of Valid) | Graph | Missing |
|---|---|---|---|---|---|
| 1 | ID [integer] |
Mean (sd) : 50.5 (29) min < med < max: 1 < 50.5 < 100 IQR (CV) : 49.5 (0.6) |
100 distinct values (Integer sequence) |
 |
0 (0.0%) |
| 2 | AGE [integer] |
Mean (sd) : 44.4 (11.7) min < med < max: 20 < 44 < 69 IQR (CV) : 20.2 (0.3) |
43 distinct values |  |
0 (0.0%) |
| 3 | AGE_GROUP [factor] |
1. 20-39 2. 30-34 3. 35-39 4. 40-44 5. 45-49 6. 50-54 7. 55-59 8. 60-69 |
10 (10.0%) 15 (15.0%) 12 (12.0%) 15 (15.0%) 13 (13.0%) 8 ( 8.0%) 17 (17.0%) 10 (10.0%) |
 |
0 (0.0%) |
| 4 | CHD [factor] |
1. No 2. Yes |
57 (57.0%) 43 (43.0%) |
 |
0 (0.0%) |
¿Cómo es la relación entre CHD y AGE?
Con el objetivo de analizar la relación entre CHD y AGE, como en el caso de la regresión lineal, construimos un scatterplot.
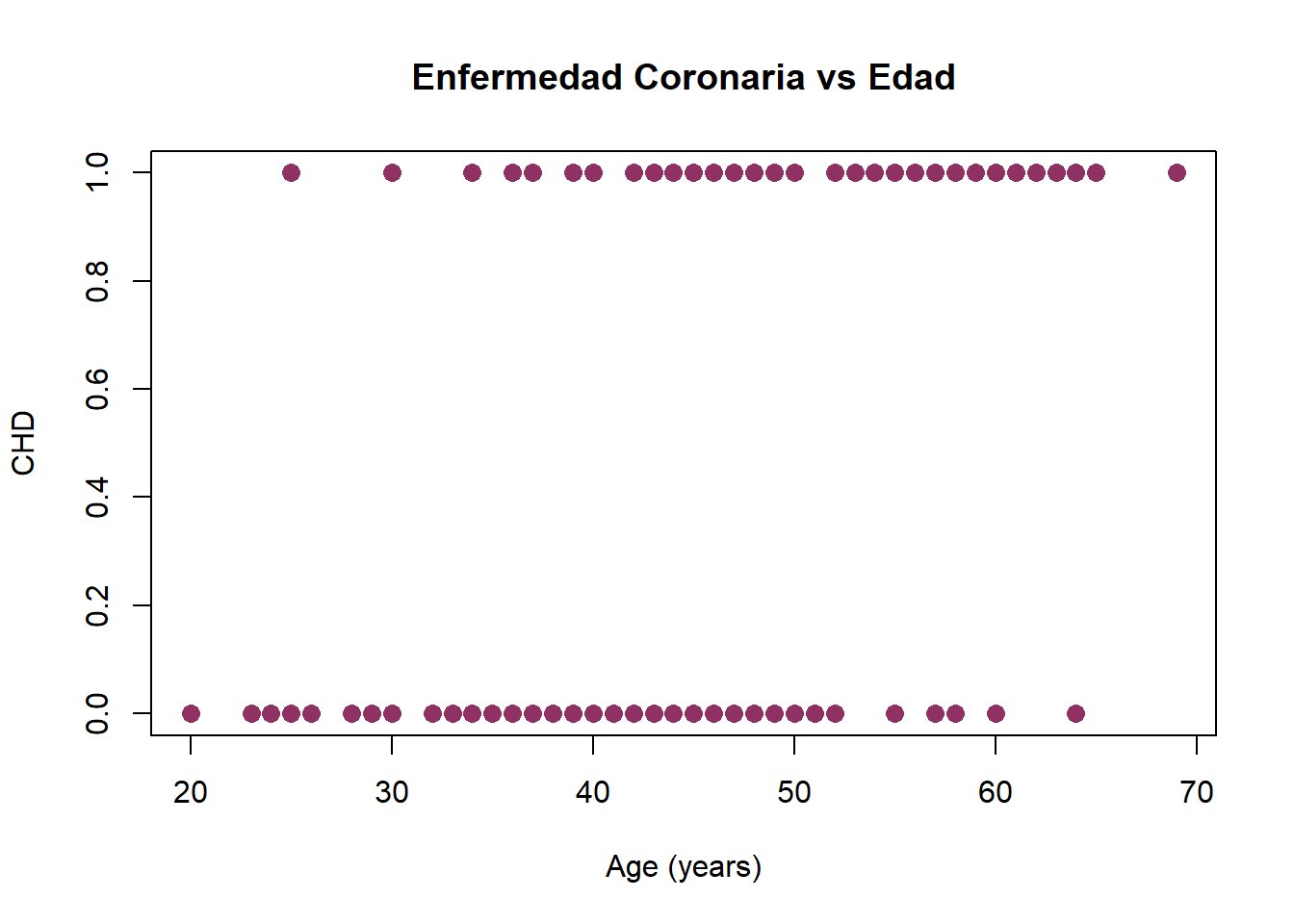
¿Podemos ajustar un Modelo de Regresión Lineal Simple?
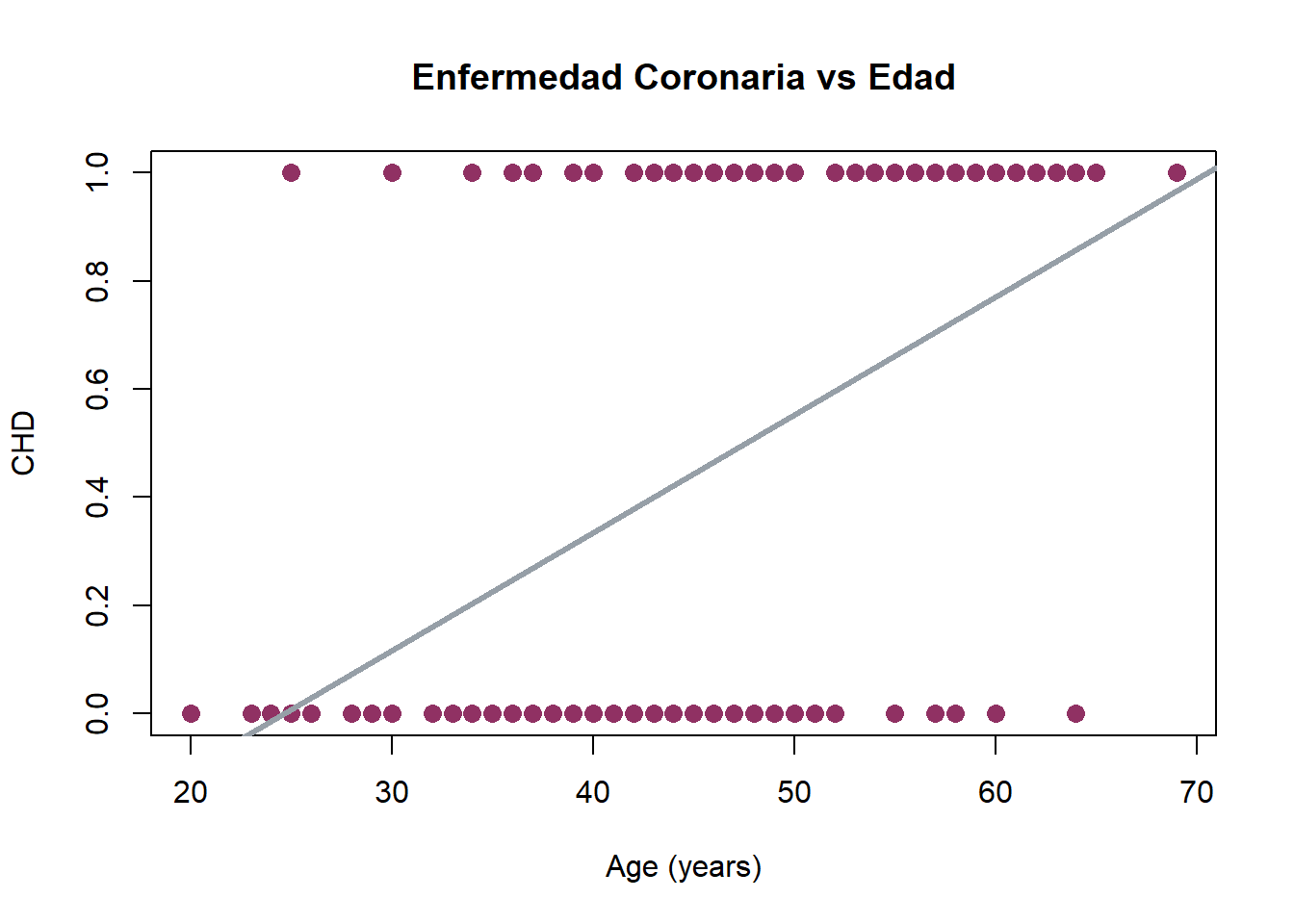 \[
\operatorname{CHD\_} = -0.54 + 0.02(\operatorname{AGE}) + \epsilon
\]
\[
\operatorname{CHD\_} = -0.54 + 0.02(\operatorname{AGE}) + \epsilon
\]
Analicemos la variable dependiente CHD por AGE_GROUP. Si calculamos la proporción de “Yes for CHD” en cada grupo de edad:
| CHD:No | CHD:Yes | n | p | |
|---|---|---|---|---|
| 20-39 | 9 | 1 | 10 | 0.10 |
| 30-34 | 13 | 2 | 15 | 0.13 |
| 35-39 | 9 | 3 | 12 | 0.25 |
| 40-44 | 10 | 5 | 15 | 0.33 |
| 45-49 | 7 | 6 | 13 | 0.46 |
| 50-54 | 3 | 5 | 8 | 0.62 |
| 55-59 | 4 | 13 | 17 | 0.76 |
| 60-69 | 2 | 8 | 10 | 0.80 |
| Sum | 57 | 43 | 100 | 0.43 |
Si hacemos un gráfico de la proporción de CHD=Yes en cada grupo de edad:
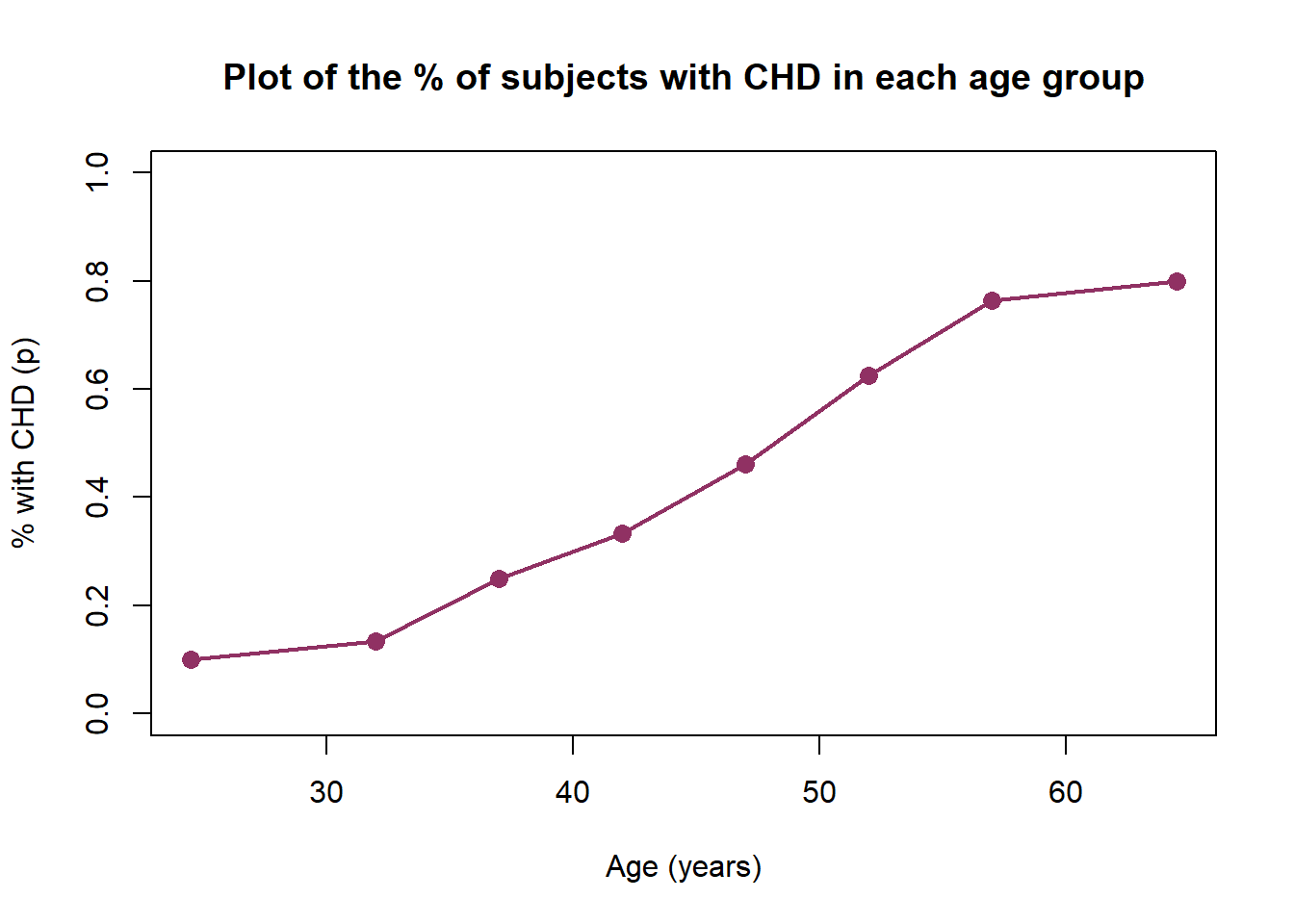
La curva representa una estimación de \(E[Y|x]\)
La curva anterior tiene forma de \(S\) (S-shaped). Recuerda la gráfica de la distribución acumulada de una variable aleatoria.
La función logística puede ser utilizada para representar la estimación de \(E[Y|x]\)
La función logística o curva logística es una curva S-shaped dada por
\[f(x)=\dfrac{L}{1+e^{-k(x-x_0)}}\] donde
- \(x_0\) es el valor de x en el punto medio de la curva
- \(L\) es el valor máximo de la curva
- \(k\) es la tasa de crecimiento
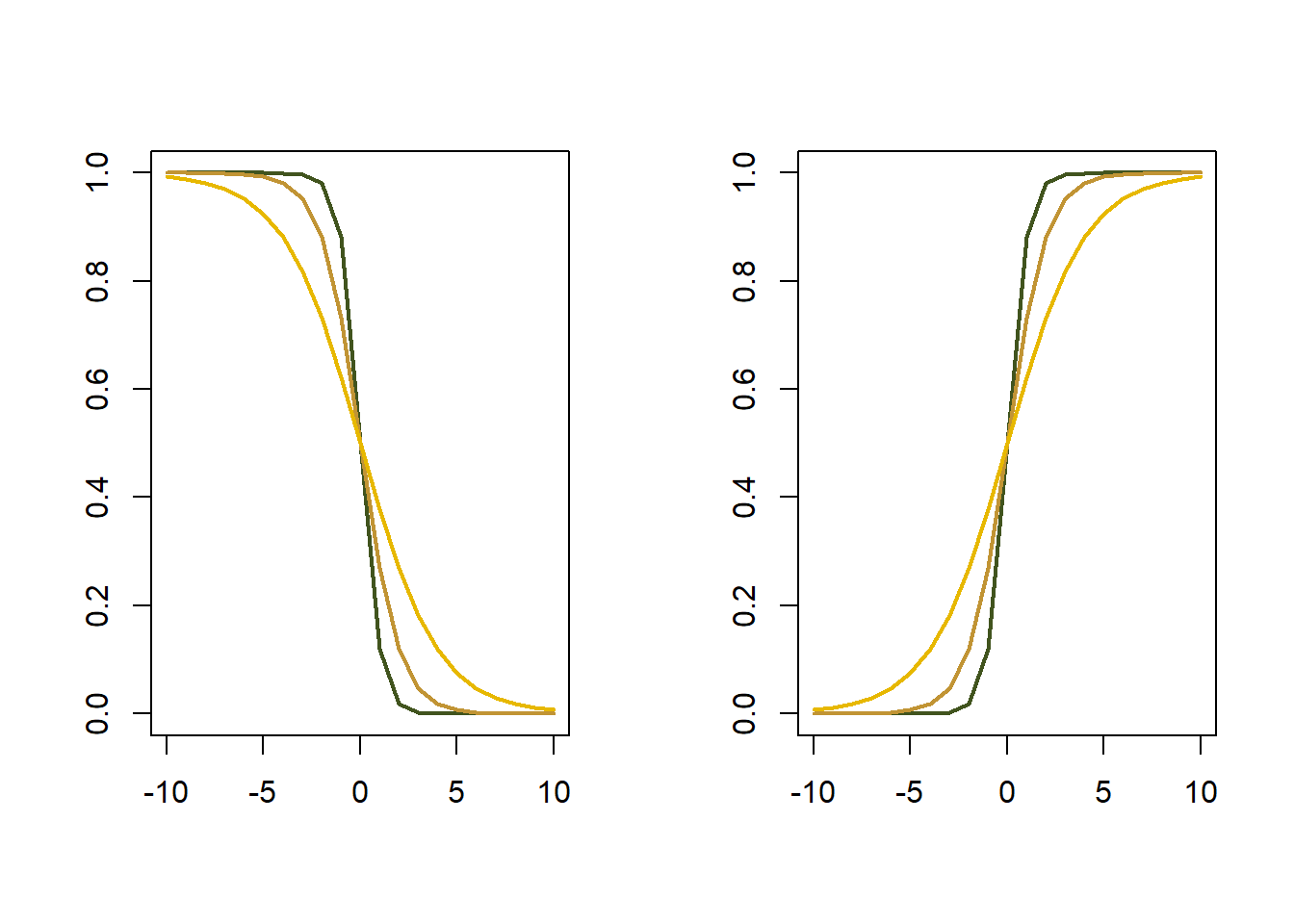
Recapitulando, la variable dependiente binaria es tal que:
\[ y_i \sim \text{Bernoulli}(\pi_i) \]
donde \(\pi_i\) es la probabilidad de \(y_i=1\) y
\[ \pi_i = \dfrac{1}{1+e^{-(\beta_0+\beta_1x_i)}} \] Como \(0<\pi_i<1\), para conseguir \(E[Y|x]\) sea un número entre \(-\infty\) y \(+\infty\), obtenemos \(1-p_i,\) la probabilidad de \(y_i=0\):
\[ 1-\pi_i = \dfrac{e^{-(\beta_0+\beta_1x_i)}}{1+e^{-(\beta_0+\beta_1x_i)}} \] El ratio de probabilidades es: \[ \dfrac{\pi_i}{1-\pi_i} = \dfrac{1}{e^{-(\beta_0+\beta_1x_i)}} \] Tomando logaritmo a ambos lados de la ecuación:
\[ \log \Bigl( \dfrac{\pi_i}{1-\pi_i} \Bigr ) = \beta_0+\beta_1x_i \] que es la ecuación de una regresión lineal simple donde la variable dependiente es \(\log ( \frac{\pi_i}{1-\pi_i})\)
El modelo ajustado es:
| Observations | 100 |
| Dependent variable | CHD |
| Type | Generalized linear model |
| Family | binomial |
| Link | logit |
| χ²(1) | 29.31 |
| Pseudo-R² (Cragg-Uhler) | 0.34 |
| Pseudo-R² (McFadden) | 0.21 |
| AIC | 111.35 |
| BIC | 116.56 |
| Est. | S.E. | z val. | p | |
|---|---|---|---|---|
| (Intercept) | -5.31 | 1.13 | -4.68 | 0.00 |
| AGE | 0.11 | 0.02 | 4.61 | 0.00 |
| Standard errors: MLE |
-
El signo del parámetro (coeficiente) estimado representa el sentido de la influencia de la variable independiente sobre la variable dependiente: positivo o negativo.
-
Podemos utilizar el std.error para construir intervalos de confianza sobre los parámetros del modelo. Tener en cuenta que se utiliza la distribución N(0,1)
-
Utilizamos MLE no MCO.
-
La interpretación de parámetros estimados no es la misma!.